

必要なのはパッチだけ?(コンバージョンミキサー
)これは紙のパッチをPyTorchで実装したものです。必要なのはパッチだけですか?
。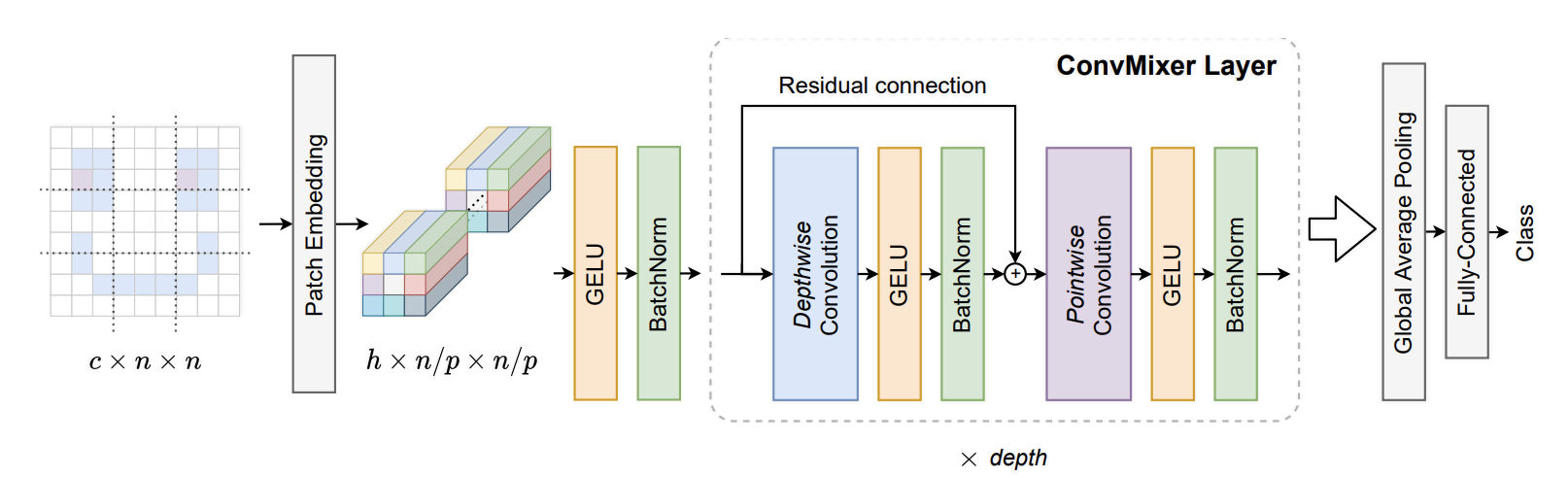
ConvMixerは、チャンネルミキシングにはコンボリューションを使用し、空間ミキシングには奥行きコンボリューションを使用します。スペース全体でフルMLPではなく畳み込みなので、VITやMLPミキサーとは対照的に、近くのバッチのみをミキシングします。また、MLPミキサーはミキシングごとに2層のMLPを使用し、ConvMixerはミキシングごとに1層のMLPを使用します
。この論文では、チャネルミキシング全体の残留接続を削除し(点単位の畳み込み)、空間ミキシングでは残留接続のみにする(深さ方向の畳み込み)ことを推奨しています。また、
レイヤー正規化の代わりにバッチ正規化を使用します。36import torch
37from torch import nn
38
39from labml_helpers.module import Module
40from labml_nn.utils import clone_module_list43class ConvMixerLayer(Module):d_modelはパッチ埋め込みのチャンネル数、kernel_sizeは空間畳み込みのカーネルの大きさです
52 def __init__(self, d_model: int, kernel_size: int):57 super().__init__()深度方向の畳み込みは、チャンネルごとに別々の畳み込みになります。これは、グループの数がチャネル数と等しい畳み込み層で行います。そのため、各チャンネルはそれぞれ独自のグループになります。
61 self.depth_wise_conv = nn.Conv2d(d_model, d_model,
62 kernel_size=kernel_size,
63 groups=d_model,
64 padding=(kernel_size - 1) // 2)深さ方向の畳み込み後のアクティベーション
66 self.act1 = nn.GELU()深さ方向の畳み込み後の正規化
68 self.norm1 = nn.BatchNorm2d(d_model)点単位の畳み込みは畳み込みです。つまり、パッチ埋め込みの線形変換です
72 self.point_wise_conv = nn.Conv2d(d_model, d_model, kernel_size=1)点単位の畳み込み後のアクティベーション
74 self.act2 = nn.GELU()点単位の畳み込み後の正規化
76 self.norm2 = nn.BatchNorm2d(d_model)78 def forward(self, x: torch.Tensor):深さ方向の畳み込みの周りの残差結合について
80 residual = x深度方向の畳み込み、活性化、正規化
83 x = self.depth_wise_conv(x)
84 x = self.act1(x)
85 x = self.norm1(x)残余接続を追加
88 x += residual点単位の畳み込み、活性化、正規化
91 x = self.point_wise_conv(x)
92 x = self.act2(x)
93 x = self.norm2(x)96 return x99class PatchEmbeddings(Module):d_modelパッチ埋め込みのチャンネル数ですpatch_sizeはパッチのサイズ、in_channelsは入力画像のチャンネル数 (RGB の場合は 3)
108 def __init__(self, d_model: int, patch_size: int, in_channels: int):114 super().__init__()カーネルサイズでストライドの長さがパッチサイズと同じコンボリューションレイヤーを作成します。これは、画像をパッチに分割し、各パッチで線形変換を行うのと同じです
。119 self.conv = nn.Conv2d(in_channels, d_model, kernel_size=patch_size, stride=patch_size)アクティベーション機能
121 self.act = nn.GELU()バッチ正規化
123 self.norm = nn.BatchNorm2d(d_model)x形状の入力画像です[batch_size, channels, height, width]
125 def forward(self, x: torch.Tensor):畳み込み層を適用
130 x = self.conv(x)アクティベーションと正規化
132 x = self.act(x)
133 x = self.norm(x)136 return x139class ClassificationHead(Module):d_modelはパッチ埋め込みのチャンネル数、n_classes分類タスク内のクラス数です
149 def __init__(self, d_model: int, n_classes: int):154 super().__init__()アベレージプール
156 self.pool = nn.AdaptiveAvgPool2d((1, 1))リニアレイヤー
158 self.linear = nn.Linear(d_model, n_classes)160 def forward(self, x: torch.Tensor):平均プーリング
162 x = self.pool(x)x
埋め込みを入れると、形が整います [batch_size, d_model, 1, 1]
164 x = x[:, :, 0, 0]リニアレイヤー
166 x = self.linear(x)169 return x172class ConvMixer(Module):conv_mixer_layer単一の ConvMixer レイヤーのコピーです。そのコピーを作成して ConvMixer を作成します。n_layersは ConvMixer レイヤーの数 (または深さ) です。patch_embパッチ埋め込みレイヤーです。classification分類責任者です。
n_layers
179 def __init__(self, conv_mixer_layer: ConvMixerLayer, n_layers: int,
180 patch_emb: PatchEmbeddings,
181 classification: ClassificationHead):189 super().__init__()パッチ埋め込み
191 self.patch_emb = patch_emb分類ヘッド
193 self.classification = classificationx形状の入力画像です[batch_size, channels, height, width]
197 def forward(self, x: torch.Tensor):パッチの埋め込みを入手してください。[batch_size, d_model, height / patch_size, width / patch_size]
これにより形状のテンソルが得られます
202 x = self.patch_emb(x)205 for layer in self.conv_mixer_layers:
206 x = layer(x)ロジットを取得するための分類ヘッド
209 x = self.classification(x)212 return x