

U-Net model for Denoising Diffusion Probabilistic Models (DDPM)
This is a U-Net based model to predict noise .
U-Net is a gets it's name from the U shape in the model diagram. It processes a given image by progressively lowering (halving) the feature map resolution and then increasing the resolution. There are pass-through connection at each resolution.
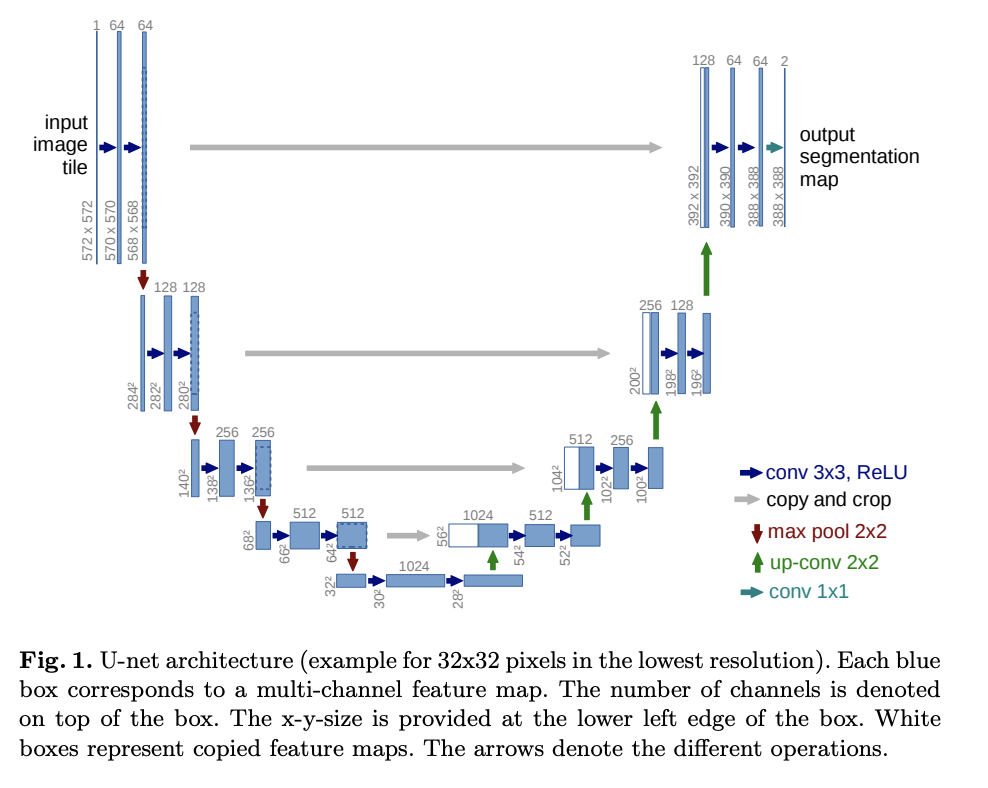
This implementation contains a bunch of modifications to original U-Net (residual blocks, multi-head attention) and also adds time-step embeddings .
24import math
25from typing import Optional, Tuple, Union, List
26
27import torch
28from torch import nn31class Swish(nn.Module):38 def forward(self, x):
39 return x * torch.sigmoid(x)Embeddings for
42class TimeEmbedding(nn.Module):n_channelsis the number of dimensions in the embedding
47 def __init__(self, n_channels: int):51 super().__init__()
52 self.n_channels = n_channelsFirst linear layer
54 self.lin1 = nn.Linear(self.n_channels // 4, self.n_channels)Activation
56 self.act = Swish()Second linear layer
58 self.lin2 = nn.Linear(self.n_channels, self.n_channels)60 def forward(self, t: torch.Tensor):70 half_dim = self.n_channels // 8
71 emb = math.log(10_000) / (half_dim - 1)
72 emb = torch.exp(torch.arange(half_dim, device=t.device) * -emb)
73 emb = t[:, None] * emb[None, :]
74 emb = torch.cat((emb.sin(), emb.cos()), dim=1)Transform with the MLP
77 emb = self.act(self.lin1(emb))
78 emb = self.lin2(emb)81 return embResidual block
A residual block has two convolution layers with group normalization. Each resolution is processed with two residual blocks.
84class ResidualBlock(nn.Module):in_channelsis the number of input channelsout_channelsis the number of input channelstime_channelsis the number channels in the time step () embeddingsn_groupsis the number of groups for group normalizationdropoutis the dropout rate
92 def __init__(self, in_channels: int, out_channels: int, time_channels: int,
93 n_groups: int = 32, dropout: float = 0.1):101 super().__init__()Group normalization and the first convolution layer
103 self.norm1 = nn.GroupNorm(n_groups, in_channels)
104 self.act1 = Swish()
105 self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=(3, 3), padding=(1, 1))Group normalization and the second convolution layer
108 self.norm2 = nn.GroupNorm(n_groups, out_channels)
109 self.act2 = Swish()
110 self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=(3, 3), padding=(1, 1))If the number of input channels is not equal to the number of output channels we have to project the shortcut connection
114 if in_channels != out_channels:
115 self.shortcut = nn.Conv2d(in_channels, out_channels, kernel_size=(1, 1))
116 else:
117 self.shortcut = nn.Identity()Linear layer for time embeddings
120 self.time_emb = nn.Linear(time_channels, out_channels)
121 self.time_act = Swish()
122
123 self.dropout = nn.Dropout(dropout)xhas shape[batch_size, in_channels, height, width]thas shape[batch_size, time_channels]
125 def forward(self, x: torch.Tensor, t: torch.Tensor):First convolution layer
131 h = self.conv1(self.act1(self.norm1(x)))Add time embeddings
133 h += self.time_emb(self.time_act(t))[:, :, None, None]Second convolution layer
135 h = self.conv2(self.dropout(self.act2(self.norm2(h))))Add the shortcut connection and return
138 return h + self.shortcut(x)141class AttentionBlock(nn.Module):n_channelsis the number of channels in the inputn_headsis the number of heads in multi-head attentiond_kis the number of dimensions in each headn_groupsis the number of groups for group normalization
148 def __init__(self, n_channels: int, n_heads: int = 1, d_k: int = None, n_groups: int = 32):155 super().__init__()Default d_k
158 if d_k is None:
159 d_k = n_channelsNormalization layer
161 self.norm = nn.GroupNorm(n_groups, n_channels)Projections for query, key and values
163 self.projection = nn.Linear(n_channels, n_heads * d_k * 3)Linear layer for final transformation
165 self.output = nn.Linear(n_heads * d_k, n_channels)Scale for dot-product attention
167 self.scale = d_k ** -0.5169 self.n_heads = n_heads
170 self.d_k = d_kxhas shape[batch_size, in_channels, height, width]thas shape[batch_size, time_channels]
172 def forward(self, x: torch.Tensor, t: Optional[torch.Tensor] = None):t
is not used, but it's kept in the arguments because for the attention layer function signature to match with ResidualBlock
.
179 _ = tGet shape
181 batch_size, n_channels, height, width = x.shapeChange x
to shape [batch_size, seq, n_channels]
183 x = x.view(batch_size, n_channels, -1).permute(0, 2, 1)Get query, key, and values (concatenated) and shape it to [batch_size, seq, n_heads, 3 * d_k]
185 qkv = self.projection(x).view(batch_size, -1, self.n_heads, 3 * self.d_k)Split query, key, and values. Each of them will have shape [batch_size, seq, n_heads, d_k]
187 q, k, v = torch.chunk(qkv, 3, dim=-1)Calculate scaled dot-product
189 attn = torch.einsum('bihd,bjhd->bijh', q, k) * self.scaleSoftmax along the sequence dimension
191 attn = attn.softmax(dim=2)Multiply by values
193 res = torch.einsum('bijh,bjhd->bihd', attn, v)Reshape to [batch_size, seq, n_heads * d_k]
195 res = res.view(batch_size, -1, self.n_heads * self.d_k)Transform to [batch_size, seq, n_channels]
197 res = self.output(res)Add skip connection
200 res += xChange to shape [batch_size, in_channels, height, width]
203 res = res.permute(0, 2, 1).view(batch_size, n_channels, height, width)206 return resDown block
This combines ResidualBlock
and AttentionBlock
. These are used in the first half of U-Net at each resolution.
209class DownBlock(nn.Module):216 def __init__(self, in_channels: int, out_channels: int, time_channels: int, has_attn: bool):
217 super().__init__()
218 self.res = ResidualBlock(in_channels, out_channels, time_channels)
219 if has_attn:
220 self.attn = AttentionBlock(out_channels)
221 else:
222 self.attn = nn.Identity()224 def forward(self, x: torch.Tensor, t: torch.Tensor):
225 x = self.res(x, t)
226 x = self.attn(x)
227 return xUp block
This combines ResidualBlock
and AttentionBlock
. These are used in the second half of U-Net at each resolution.
230class UpBlock(nn.Module):237 def __init__(self, in_channels: int, out_channels: int, time_channels: int, has_attn: bool):
238 super().__init__()The input has in_channels + out_channels
because we concatenate the output of the same resolution from the first half of the U-Net
241 self.res = ResidualBlock(in_channels + out_channels, out_channels, time_channels)
242 if has_attn:
243 self.attn = AttentionBlock(out_channels)
244 else:
245 self.attn = nn.Identity()247 def forward(self, x: torch.Tensor, t: torch.Tensor):
248 x = self.res(x, t)
249 x = self.attn(x)
250 return xMiddle block
It combines a ResidualBlock
, AttentionBlock
, followed by another ResidualBlock
. This block is applied at the lowest resolution of the U-Net.
253class MiddleBlock(nn.Module):261 def __init__(self, n_channels: int, time_channels: int):
262 super().__init__()
263 self.res1 = ResidualBlock(n_channels, n_channels, time_channels)
264 self.attn = AttentionBlock(n_channels)
265 self.res2 = ResidualBlock(n_channels, n_channels, time_channels)267 def forward(self, x: torch.Tensor, t: torch.Tensor):
268 x = self.res1(x, t)
269 x = self.attn(x)
270 x = self.res2(x, t)
271 return xScale up the feature map by
274class Upsample(nn.Module):279 def __init__(self, n_channels):
280 super().__init__()
281 self.conv = nn.ConvTranspose2d(n_channels, n_channels, (4, 4), (2, 2), (1, 1))283 def forward(self, x: torch.Tensor, t: torch.Tensor):t
is not used, but it's kept in the arguments because for the attention layer function signature to match with ResidualBlock
.
286 _ = t
287 return self.conv(x)Scale down the feature map by
290class Downsample(nn.Module):295 def __init__(self, n_channels):
296 super().__init__()
297 self.conv = nn.Conv2d(n_channels, n_channels, (3, 3), (2, 2), (1, 1))299 def forward(self, x: torch.Tensor, t: torch.Tensor):t
is not used, but it's kept in the arguments because for the attention layer function signature to match with ResidualBlock
.
302 _ = t
303 return self.conv(x)U-Net
306class UNet(nn.Module):image_channelsis the number of channels in the image. for RGB.n_channelsis number of channels in the initial feature map that we transform the image intoch_multsis the list of channel numbers at each resolution. The number of channels isch_mults[i] * n_channelsis_attnis a list of booleans that indicate whether to use attention at each resolutionn_blocksis the number ofUpDownBlocksat each resolution
311 def __init__(self, image_channels: int = 3, n_channels: int = 64,
312 ch_mults: Union[Tuple[int, ...], List[int]] = (1, 2, 2, 4),
313 is_attn: Union[Tuple[bool, ...], List[bool]] = (False, False, True, True),
314 n_blocks: int = 2):322 super().__init__()Number of resolutions
325 n_resolutions = len(ch_mults)Project image into feature map
328 self.image_proj = nn.Conv2d(image_channels, n_channels, kernel_size=(3, 3), padding=(1, 1))Time embedding layer. Time embedding has n_channels * 4
channels
331 self.time_emb = TimeEmbedding(n_channels * 4)First half of U-Net - decreasing resolution
334 down = []Number of channels
336 out_channels = in_channels = n_channelsFor each resolution
338 for i in range(n_resolutions):Number of output channels at this resolution
340 out_channels = in_channels * ch_mults[i]Add n_blocks
342 for _ in range(n_blocks):
343 down.append(DownBlock(in_channels, out_channels, n_channels * 4, is_attn[i]))
344 in_channels = out_channelsDown sample at all resolutions except the last
346 if i < n_resolutions - 1:
347 down.append(Downsample(in_channels))Combine the set of modules
350 self.down = nn.ModuleList(down)Middle block
353 self.middle = MiddleBlock(out_channels, n_channels * 4, )Second half of U-Net - increasing resolution
356 up = []Number of channels
358 in_channels = out_channelsFor each resolution
360 for i in reversed(range(n_resolutions)):n_blocks
at the same resolution
362 out_channels = in_channels
363 for _ in range(n_blocks):
364 up.append(UpBlock(in_channels, out_channels, n_channels * 4, is_attn[i]))Final block to reduce the number of channels
366 out_channels = in_channels // ch_mults[i]
367 up.append(UpBlock(in_channels, out_channels, n_channels * 4, is_attn[i]))
368 in_channels = out_channelsUp sample at all resolutions except last
370 if i > 0:
371 up.append(Upsample(in_channels))Combine the set of modules
374 self.up = nn.ModuleList(up)Final normalization and convolution layer
377 self.norm = nn.GroupNorm(8, n_channels)
378 self.act = Swish()
379 self.final = nn.Conv2d(in_channels, image_channels, kernel_size=(3, 3), padding=(1, 1))xhas shape[batch_size, in_channels, height, width]thas shape[batch_size]
381 def forward(self, x: torch.Tensor, t: torch.Tensor):Get time-step embeddings
388 t = self.time_emb(t)Get image projection
391 x = self.image_proj(x)h
will store outputs at each resolution for skip connection
394 h = [x]First half of U-Net
396 for m in self.down:
397 x = m(x, t)
398 h.append(x)Middle (bottom)
401 x = self.middle(x, t)Second half of U-Net
404 for m in self.up:
405 if isinstance(m, Upsample):
406 x = m(x, t)
407 else:Get the skip connection from first half of U-Net and concatenate
409 s = h.pop()
410 x = torch.cat((x, s), dim=1)412 x = m(x, t)Final normalization and convolution
415 return self.final(self.act(self.norm(x)))