

Patches Are All You Need? (ConvMixer)
This is a PyTorch implementation of the paper Patches Are All You Need?.
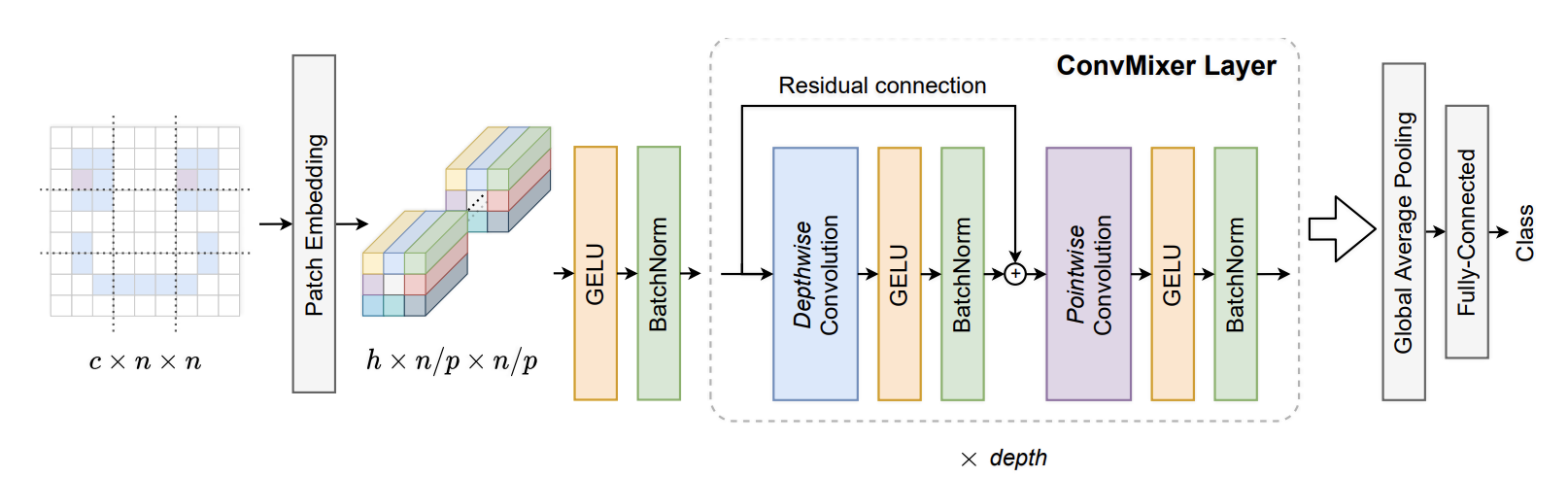
ConvMixer is Similar to MLP-Mixer. MLP-Mixer separates mixing of spatial and channel dimensions, by applying an MLP across spatial dimension and then an MLP across the channel dimension (spatial MLP replaces the ViT attention and channel MLP is the FFN of ViT).
ConvMixer uses a convolution for channel mixing and a depth-wise convolution for spatial mixing. Since it's a convolution instead of a full MLP across the space, it mixes only the nearby batches in contrast to ViT or MLP-Mixer. Also, the MLP-mixer uses MLPs of two layers for each mixing and ConvMixer uses a single layer for each mixing.
The paper recommends removing the residual connection across the channel mixing (point-wise convolution) and having only a residual connection over the spatial mixing (depth-wise convolution). They also use Batch normalization instead of Layer normalization.
Here's an experiment that trains ConvMixer on CIFAR-10.
36import torch
37from torch import nn
38
39from labml_nn.utils import clone_module_list42class ConvMixerLayer(nn.Module):d_modelis the number of channels in patch embeddings,kernel_sizeis the size of the kernel of spatial convolution,
51 def __init__(self, d_model: int, kernel_size: int):56 super().__init__()Depth-wise convolution is separate convolution for each channel. We do this with a convolution layer with the number of groups equal to the number of channels. So that each channel is it's own group.
60 self.depth_wise_conv = nn.Conv2d(d_model, d_model,
61 kernel_size=kernel_size,
62 groups=d_model,
63 padding=(kernel_size - 1) // 2)Activation after depth-wise convolution
65 self.act1 = nn.GELU()Normalization after depth-wise convolution
67 self.norm1 = nn.BatchNorm2d(d_model)Point-wise convolution is a convolution. i.e. a linear transformation of patch embeddings
71 self.point_wise_conv = nn.Conv2d(d_model, d_model, kernel_size=1)Activation after point-wise convolution
73 self.act2 = nn.GELU()Normalization after point-wise convolution
75 self.norm2 = nn.BatchNorm2d(d_model)77 def forward(self, x: torch.Tensor):For the residual connection around the depth-wise convolution
79 residual = xDepth-wise convolution, activation and normalization
82 x = self.depth_wise_conv(x)
83 x = self.act1(x)
84 x = self.norm1(x)Add residual connection
87 x += residualPoint-wise convolution, activation and normalization
90 x = self.point_wise_conv(x)
91 x = self.act2(x)
92 x = self.norm2(x)95 return xGet patch embeddings
This splits the image into patches of size and gives an embedding for each patch.
98class PatchEmbeddings(nn.Module):d_modelis the number of channels in patch embeddingspatch_sizeis the size of the patch,in_channelsis the number of channels in the input image (3 for rgb)
107 def __init__(self, d_model: int, patch_size: int, in_channels: int):113 super().__init__()We create a convolution layer with a kernel size and and stride length equal to patch size. This is equivalent to splitting the image into patches and doing a linear transformation on each patch.
118 self.conv = nn.Conv2d(in_channels, d_model, kernel_size=patch_size, stride=patch_size)Activation function
120 self.act = nn.GELU()Batch normalization
122 self.norm = nn.BatchNorm2d(d_model)xis the input image of shape[batch_size, channels, height, width]
124 def forward(self, x: torch.Tensor):Apply convolution layer
129 x = self.conv(x)Activation and normalization
131 x = self.act(x)
132 x = self.norm(x)135 return xClassification Head
They do average pooling (taking the mean of all patch embeddings) and a final linear transformation to predict the log-probabilities of the image classes.
138class ClassificationHead(nn.Module):d_modelis the number of channels in patch embeddings,n_classesis the number of classes in the classification task
148 def __init__(self, d_model: int, n_classes: int):153 super().__init__()Average Pool
155 self.pool = nn.AdaptiveAvgPool2d((1, 1))Linear layer
157 self.linear = nn.Linear(d_model, n_classes)159 def forward(self, x: torch.Tensor):Average pooling
161 x = self.pool(x)Get the embedding, x
will have shape [batch_size, d_model, 1, 1]
163 x = x[:, :, 0, 0]Linear layer
165 x = self.linear(x)168 return xConvMixer
This combines the patch embeddings block, a number of ConvMixer layers and a classification head.
171class ConvMixer(nn.Module):conv_mixer_layeris a copy of a single ConvMixer layer. We make copies of it to make ConvMixer withn_layers.n_layersis the number of ConvMixer layers (or depth), .patch_embis the patch embeddings layer.classificationis the classification head.
178 def __init__(self, conv_mixer_layer: ConvMixerLayer, n_layers: int,
179 patch_emb: PatchEmbeddings,
180 classification: ClassificationHead):188 super().__init__()Patch embeddings
190 self.patch_emb = patch_embClassification head
192 self.classification = classificationMake copies of the ConvMixer layer
194 self.conv_mixer_layers = clone_module_list(conv_mixer_layer, n_layers)xis the input image of shape[batch_size, channels, height, width]
196 def forward(self, x: torch.Tensor):Get patch embeddings. This gives a tensor of shape [batch_size, d_model, height / patch_size, width / patch_size]
.
201 x = self.patch_emb(x)Pass through ConvMixer layers
204 for layer in self.conv_mixer_layers:
205 x = layer(x)Classification head, to get logits
208 x = self.classification(x)211 return x