

校正亚当 (raDAM) 优化器
该实施基于《自适应学习率及以后的差异》一文的正式实施。
我们已经在 PyTorch 中实现了它,作为我们的 AmsGrad 实现的扩展,因此只需要实施修改即可。
在训练的初始阶段,Adam optimizer 有时会收敛到糟糕的局部最佳值;尤其是在训练变形金刚时。研究使用热身来应对这种情况;对于最初的训练步骤(热身阶段),他们使用较低的学习率。本文将问题确定为训练初始阶段自适应学习率的高方差,并使用新的校正术语来减少方差。
本文还评估了两种方差缩减机制:adam-2K:仅计算前 2k 步长的自适应学习率(在 Adam 中),而不更改参数或计算动量()。adam-eps:Adam 很大。
纠正了亚当
让和成为计算动量和自适应学习速率的函数。对亚当来说,他们是
指数移动平均线作为简单移动平均线
指数移动平均线的分布可以近似为简单移动平均线。
这里我们取最后一个梯度的简单移动平均线。满足以下条件,
这给了,
缩放反向卡方
从上面看,我们有哪里。请注意,这里是标准差,与动量不同。
缩放逆卡方是正态分布均值的逆平方分布。在哪里。
整改
他们证明了随时间变化的变化而降低。
因此,方差最小化为最大值。让最小方差为
为了确保自适应学习率具有一致的方差,我们使用以下方法校正方差
近似值
他们根据一阶扩张估计 🤪 我不明白它是如何得出的。
从分发来看,
这给了,
整改期限
我们有
在哪里。Lt and step be,然后成为 step 的整改期限。
这给了,
139import math
140from typing import Dict, Optional
141
142import torch
143
144from labml_nn.optimizers import WeightDecay
145from labml_nn.optimizers.amsgrad import AMSGrad148class RAdam(AMSGrad):初始化优化器
params是参数列表lr是学习率betas是 (,) 的元组eps是或基于optimized_updateweight_decay是在中WeightDecay定义的类的实例__init__.pyoptimized_update是一个标志,是否在添加后通过这样做来优化第二个时刻的偏差校正amsgrad是一个标志,指示是使用 AmsGrad 还是回退到普通的 Adamdegenerate_to_sgd纠正术语难以处理时是否使用 sgd。defaults是组值的默认字典。当你想扩展类时,这很有用RAdam。
155 def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8,
156 weight_decay: WeightDecay = WeightDecay(),
157 optimized_update: bool = True,
158 amsgrad=False,
159 degenerated_to_sgd=True, defaults=None):175 self.degenerated_to_sgd = degenerated_to_sgd
176 super().__init__(params, lr, betas, eps, weight_decay, optimized_update, amsgrad, defaults)178 def step_param(self, state: Dict[str, any], group: Dict[str, any], grad: torch.Tensor, param: torch.nn.Parameter):计算体重衰减
189 grad = self.weight_decay(param, grad, group)Get an d; 即不进行偏差校正
192 m, v = self.get_mv(state, group, grad)计算优化器步数
195 state['step'] += 1执行 raDAM 更新
198 self.r_adam_update(state, group, param, m, v)计算整改期限
200 @staticmethod
201 def calc_rectification_term(beta2: float, step: int) -> Optional[float]:207 beta2_t = beta2 ** step209 rho_inf = 2 / (1 - beta2) - 1211 rho = rho_inf - 2 * step * beta2_t / (1 - beta2_t)什么时候是可以处理的。我们稍微保守一点,因为它是近似值
215 if rho >= 5:217 r2 = (rho - 4) / (rho_inf - 4) * (rho - 2) / rho * rho_inf / (rho_inf - 2)
218 return math.sqrt(r2)
219 else:
220 return None222 def r_adam_update(self, state: Dict[str, any], group: Dict[str, any], param: torch.nn.Parameter,
223 m: torch.Tensor, v: torch.Tensor):获取和
235 beta1, beta2 = group['betas']偏差校正术语,
237 bias_correction1 = 1 - beta1 ** state['step']偏差校正术语,
239 bias_correction2 = 1 - beta2 ** state['step']
240
241 r = self.calc_rectification_term(beta2, state['step'])获取学习率
244 lr = self.get_lr(state, group)如果是棘手的
247 if r is not None:是否通过组合标量计算来优化计算
249 if self.optimized_update:分母
251 denominator = v.sqrt().add_(group['eps'])步长
253 step_size = lr * math.sqrt(bias_correction2) * r / bias_correction1更新参数
256 param.data.addcdiv_(m, denominator, value=-step_size)无需优化的计算
258 else:分母
260 denominator = (v.sqrt() / math.sqrt(bias_correction2)).add_(group['eps'])步长
262 step_size = lr * r / bias_correction1更新参数
265 param.data.addcdiv_(m, denominator, value=-step_size)如果难以解决,那就用势头做新加坡元
268 elif self.degenerated_to_sgd:步长
270 step_size = lr / bias_correction1更新参数
273 param.data.add_(m, alpha=-step_size)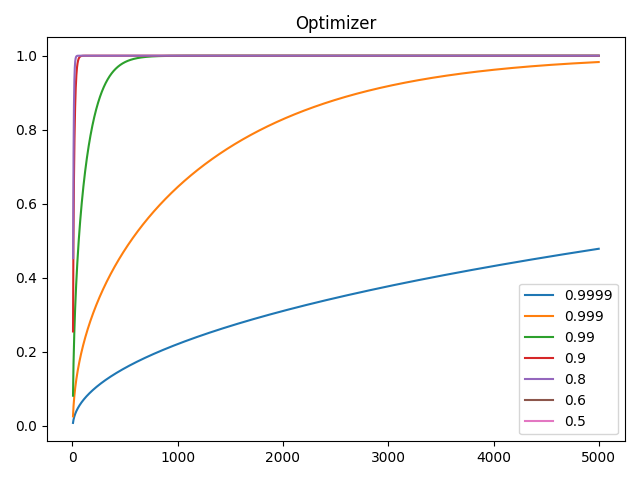
276def _test_rectification_term():282 import matplotlib.pyplot as plt
283 import numpy as np
284
285 beta2 = [0.9999, 0.999, 0.99, 0.9, 0.8, 0.6, 0.5]
286 plt.plot(np.arange(1, 5_000), [[RAdam.calc_rectification_term(b, i) for b in beta2] for i in range(1, 5_000)])
287 plt.legend(beta2)
288 plt.title("Optimizer")
289 plt.show()
290
291
292if __name__ == '__main__':
293 _test_rectification_term()