

14from typing import Dict
15
16from labml_nn.optimizers import WeightDecay
17from labml_nn.optimizers.amsgrad import AMSGrad初始化优化器
params是参数列表lr是学习率betas是 (,) 的元组eps是或基于optimized_updateweight_decay是在中WeightDecay定义的类的实例__init__.py- “optimized_update” 是一个标志,在添加后是否要优化第二个时刻的偏差校正
amsgrad是一个标志,指示是使用 AmsGrad 还是回退到普通的 Adamwarmup预热步数d_model型号尺寸;即变压器中的尺寸数defaults是组值的默认字典。当你想扩展类时,这很有用AdamWarmup。
27 def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-16,
28 weight_decay: WeightDecay = WeightDecay(),
29 optimized_update: bool = True,
30 amsgrad=False,
31 warmup=0, d_model=512, defaults=None):49 defaults = {} if defaults is None else defaults
50 defaults.update(dict(warmup=warmup))
51 super().__init__(params, lr, betas, eps, weight_decay, optimized_update, amsgrad, defaults)
52 self.d_model = d_model54 def get_lr(self, state: Dict[str, any], group: Dict[str, any]):62 factor = min(state['step'] ** (-0.5), state['step'] * group['warmup'] ** (-1.5))64 return group['lr'] * self.d_model ** (-0.5) * factor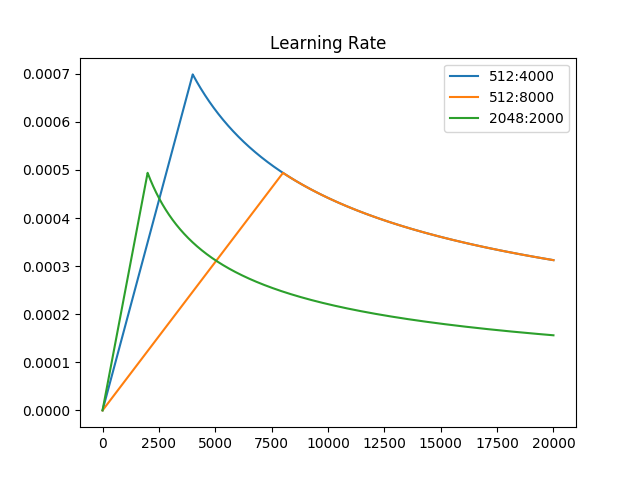
67def _test_noam_lr():73 import matplotlib.pyplot as plt
74 import numpy as np
75 from torch import nn
76
77 model = nn.Linear(10, 10)
78 opts = [Noam(model.parameters(), d_model=512, warmup=4000, lr=1),
79 Noam(model.parameters(), d_model=512, warmup=8000, lr=1),
80 Noam(model.parameters(), d_model=2048, warmup=2000, lr=1)]
81 plt.plot(np.arange(1, 20000), [[opt.get_lr({'step': i}, opt.defaults) for opt in opts] for i in range(1, 20000)])
82 plt.legend(["512:4000", "512:8000", "2048:2000"])
83 plt.title("Learning Rate")
84 plt.show()
85
86
87if __name__ == '__main__':
88 _test_noam_lr()