

修正されたアダム (RaDAM) オプティマイザー
この実装は、「適応学習率とその後の差異に関する論文」の公式実装に基づいています。
amsGrad実装の拡張としてPyTorchに実装したので、実装する必要があるのは変更だけです。
アダムオプティマイザーは、トレーニングの初期段階、特にトランスフォーマーをトレーニングしているときに、不適切な局所最適値に収束することがあります。研究者はこれに対抗するためにウォームアップを使います。最初のトレーニングステップ(ウォームアップ段階)では低い学習率を使います。本稿では、トレーニングの初期段階における適応学習率のばらつきが大きいという問題を特定し、分散を減らすための新しい修正項を用いてその問題に対処しています
。この論文では、2つの分散削減メカニズムについても評価しています。Adam-2k:パラメータを変更したり、運動量を計算したりせずに、最初の2kステップでは(Adamで)適応学習率のみを計算します()。Adam-EPS: アダム・ウィズ・ラージ・ウィズ・ラージ
.正義のアダム
運動量と適応学習率を計算する関数としましょう。アダムにとって、彼らは
単純移動平均としての指数移動平均
指数移動平均の分布は、単純な移動平均として近似できます。
ここでは、最後の勾配の単純移動平均を取っています。以下を満たし、
これにより、
スケーリングされた逆カイ二乗
上から見ると、場所がわかります。これは標準偏差であり、運動量とは異なることに注意してください
。スケーリングされた逆カイ二乗は、正規分布の平均の二乗逆数の分布です。どこ。
整流
時間とともにばらつきが小さくなることを証明しています。
したがって、分散は最大値、つまりで最小化されます。最小分散を次の式にしましょう
適応型学習率のばらつきが一貫していることを確認するために、差異を以下のように修正します。
おおよその値
どう導き出されたのかわからなかった 🤪 の一次展開に基づいて見積もっています。
私たちが持っているディストリビューションから、
これにより、
修正期間
私たちは持っています
どこが.一歩を踏み出して、段階的な修正項になりなさい
。これにより、
139import math
140from typing import Dict, Optional
141
142import torch
143
144from labml_nn.optimizers import WeightDecay
145from labml_nn.optimizers.amsgrad import AMSGrad148class RAdam(AMSGrad):オプティマイザを初期化
paramsはパラメータのリストですlrは学習率betas(,) のタプルですepsまたはそれに基づいているoptimized_updateweight_decayWeightDecayで定義されているクラスのインスタンスです__init__.pyoptimized_updateセカンドモーメントのバイアス補正を加算してから行うことで最適化するか否かのフラグですamsgradamsGradを使用するか、プレーンなAdamにフォールバックするかを示すフラグですdegenerate_to_sgd修正項が扱いにくい場合に sgd を使うかどうか。defaultsグループ値のデフォルト辞書です。これは、クラスを拡張する場合に便利ですRAdam。
155 def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8,
156 weight_decay: WeightDecay = WeightDecay(),
157 optimized_update: bool = True,
158 amsgrad=False,
159 degenerated_to_sgd=True, defaults=None):175 self.degenerated_to_sgd = degenerated_to_sgd
176 super().__init__(params, lr, betas, eps, weight_decay, optimized_update, amsgrad, defaults)与えられたパラメータテンソルの更新ステップを実行する
stateはパラメーター (テンソル) のオプティマイザー状態ですgroupパラメータグループのオプティマイザ属性を格納しますgradパラメータの現在の勾配テンソルですparamはパラメータテンソル
178 def step_param(self, state: Dict[str, any], group: Dict[str, any], grad: torch.Tensor, param: torch.nn.Parameter):体重減少の計算
189 grad = self.weight_decay(param, grad, group)Get と; つまり、バイアス補正なし
192 m, v = self.get_mv(state, group, grad)オプティマイザーステップ数の計算
195 state['step'] += 1RaDAM アップデートを実行
198 self.r_adam_update(state, group, param, m, v)修正期間の計算
200 @staticmethod
201 def calc_rectification_term(beta2: float, step: int) -> Optional[float]:207 beta2_t = beta2 ** step209 rho_inf = 2 / (1 - beta2) - 1211 rho = rho_inf - 2 * step * beta2_t / (1 - beta2_t)どんなときでも扱いやすい。おおよその値なので、もう少し保守的にしています
215 if rho >= 5:217 r2 = (rho - 4) / (rho_inf - 4) * (rho - 2) / rho * rho_inf / (rho_inf - 2)
218 return math.sqrt(r2)
219 else:
220 return NoneRadAM パラメータの更新を行います
stateはパラメーター (テンソル) のオプティマイザー状態ですgroupパラメータグループのオプティマイザ属性を格納しますparamはパラメータテンソルm未補正の第1モーメントと第2モーメントで、バイアス補正なしv
222 def r_adam_update(self, state: Dict[str, any], group: Dict[str, any], param: torch.nn.Parameter,
223 m: torch.Tensor, v: torch.Tensor):取得して
235 beta1, beta2 = group['betas']のバイアス補正用語
237 bias_correction1 = 1 - beta1 ** state['step']のバイアス補正用語
239 bias_correction2 = 1 - beta2 ** state['step']
240
241 r = self.calc_rectification_term(beta2, state['step'])学習率を取得
244 lr = self.get_lr(state, group)治りにくい場合
247 if r is not None:スカラー計算を組み合わせて計算を最適化するかどうか
249 if self.optimized_update:分母
251 denominator = v.sqrt().add_(group['eps'])ステップサイズ
253 step_size = lr * math.sqrt(bias_correction2) * r / bias_correction1パラメータを更新
256 param.data.addcdiv_(m, denominator, value=-step_size)最適化なしの計算
258 else:分母
260 denominator = (v.sqrt() / math.sqrt(bias_correction2)).add_(group['eps'])ステップサイズ
262 step_size = lr * r / bias_correction1パラメータを更新
265 param.data.addcdiv_(m, denominator, value=-step_size)手に負えないなら勢いをつけてSGDをやりましょう
268 elif self.degenerated_to_sgd:ステップサイズ
270 step_size = lr / bias_correction1パラメータを更新
273 param.data.add_(m, alpha=-step_size)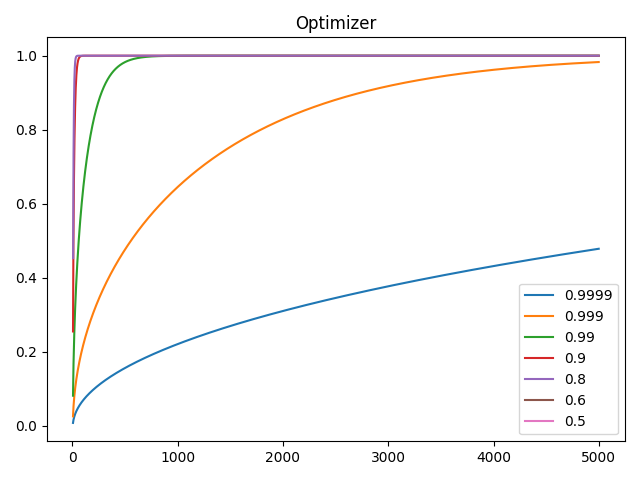
276def _test_rectification_term():282 import matplotlib.pyplot as plt
283 import numpy as np
284
285 beta2 = [0.9999, 0.999, 0.99, 0.9, 0.8, 0.6, 0.5]
286 plt.plot(np.arange(1, 5_000), [[RAdam.calc_rectification_term(b, i) for b in beta2] for i in range(1, 5_000)])
287 plt.legend(beta2)
288 plt.title("Optimizer")
289 plt.show()
290
291
292if __name__ == '__main__':
293 _test_rectification_term()