

ノイズ除去拡散確率モデル (DDPM) 用の U-Net モデル
これは U-Net ベースのノイズ予測モデルです。
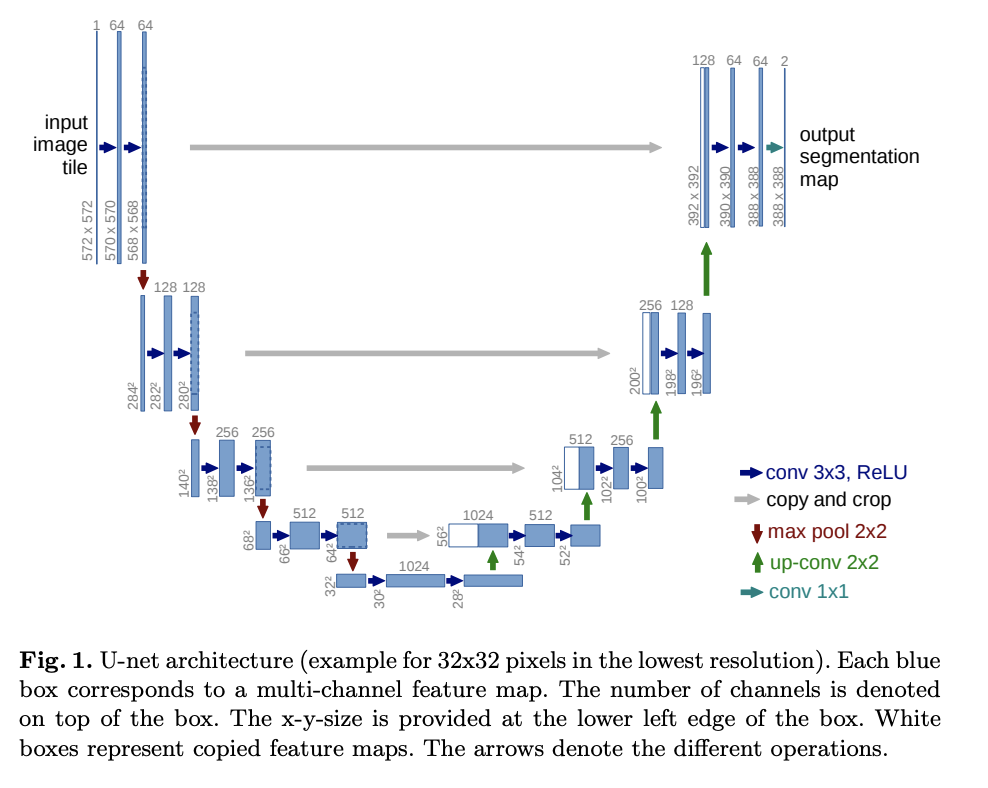
U-Netは、モデル図のU字形にちなんで名付けられました。特徴マップの解像度を段階的に低く (半分に)、次に解像度を上げることによって、特定の画像を処理します。各解像度にはパススルー接続があります
。
この実装には、オリジナルの U-Net に多数の変更(残留ブロック、マルチヘッドアテンション)が含まれており、タイムステップの埋め込みも追加されています。
24import math
25from typing import Optional, Tuple, Union, List
26
27import torch
28from torch import nn
29
30from labml_helpers.module import Module33class Swish(Module):40 def forward(self, x):
41 return x * torch.sigmoid(x)の埋め込み
44class TimeEmbedding(nn.Module):n_channelsは埋め込みの次元数です
49 def __init__(self, n_channels: int):53 super().__init__()
54 self.n_channels = n_channels第 1 線形レイヤー
56 self.lin1 = nn.Linear(self.n_channels // 4, self.n_channels)アクティベーション
58 self.act = Swish()2 番目の線形レイヤー
60 self.lin2 = nn.Linear(self.n_channels, self.n_channels)62 def forward(self, t: torch.Tensor):72 half_dim = self.n_channels // 8
73 emb = math.log(10_000) / (half_dim - 1)
74 emb = torch.exp(torch.arange(half_dim, device=t.device) * -emb)
75 emb = t[:, None] * emb[None, :]
76 emb = torch.cat((emb.sin(), emb.cos()), dim=1)MLP によるトランスフォーメーション
79 emb = self.act(self.lin1(emb))
80 emb = self.lin2(emb)83 return emb86class ResidualBlock(Module):in_channelsは入力チャンネル数out_channelsは入力チャンネル数time_channelsはタイムステップ () 埋め込みの数チャンネルですn_groupsはグループ正規化の対象となるグループの数ですdropout脱落率です
94 def __init__(self, in_channels: int, out_channels: int, time_channels: int,
95 n_groups: int = 32, dropout: float = 0.1):103 super().__init__()グループ正規化と最初の畳み込み層
105 self.norm1 = nn.GroupNorm(n_groups, in_channels)
106 self.act1 = Swish()
107 self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=(3, 3), padding=(1, 1))グループ正規化と 2 番目の畳み込み層
110 self.norm2 = nn.GroupNorm(n_groups, out_channels)
111 self.act2 = Swish()
112 self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=(3, 3), padding=(1, 1))入力チャンネルの数が出力チャンネルの数と等しくない場合は、ショートカット接続を投影する必要があります。
116 if in_channels != out_channels:
117 self.shortcut = nn.Conv2d(in_channels, out_channels, kernel_size=(1, 1))
118 else:
119 self.shortcut = nn.Identity()時間埋め込み用の線形レイヤー
122 self.time_emb = nn.Linear(time_channels, out_channels)
123 self.time_act = Swish()
124
125 self.dropout = nn.Dropout(dropout)x形がある[batch_size, in_channels, height, width]t形がある[batch_size, time_channels]
127 def forward(self, x: torch.Tensor, t: torch.Tensor):最初の畳み込み層
133 h = self.conv1(self.act1(self.norm1(x)))時間埋め込みを追加
135 h += self.time_emb(self.time_act(t))[:, :, None, None]2 番目の畳み込み層
137 h = self.conv2(self.dropout(self.act2(self.norm2(h))))ショートカット接続を追加して戻る
140 return h + self.shortcut(x)143class AttentionBlock(Module):n_channelsは入力のチャンネル数n_headsマルチヘッド・アテンションのヘッド数ですd_kは各ヘッドの次元数ですn_groupsはグループ正規化の対象となるグループの数です
150 def __init__(self, n_channels: int, n_heads: int = 1, d_k: int = None, n_groups: int = 32):157 super().__init__()デフォルト d_k
160 if d_k is None:
161 d_k = n_channels正規化レイヤー
163 self.norm = nn.GroupNorm(n_groups, n_channels)クエリ、キー、値の投影
165 self.projection = nn.Linear(n_channels, n_heads * d_k * 3)最終変換用の線形レイヤー
167 self.output = nn.Linear(n_heads * d_k, n_channels)ドットプロダクト・アテンション・スケール
169 self.scale = d_k ** -0.5171 self.n_heads = n_heads
172 self.d_k = d_kx形がある[batch_size, in_channels, height, width]t形がある[batch_size, time_channels]
174 def forward(self, x: torch.Tensor, t: Optional[torch.Tensor] = None):t
は使われていませんが、ResidualBlock
アテンションレイヤーの関数シグネチャとのマッチングのため引数には残されています。
181 _ = tシェイプを取得
183 batch_size, n_channels, height, width = x.shapex
形状に変更 [batch_size, seq, n_channels]
185 x = x.view(batch_size, n_channels, -1).permute(0, 2, 1)クエリ、キー、値 (連結) を取得し、以下のように形を整えます [batch_size, seq, n_heads, 3 * d_k]
187 qkv = self.projection(x).view(batch_size, -1, self.n_heads, 3 * self.d_k)クエリ、キー、値を分割します。それぞれに形があります [batch_size, seq, n_heads, d_k]
189 q, k, v = torch.chunk(qkv, 3, dim=-1)スケーリングされたドットプロダクトの計算
191 attn = torch.einsum('bihd,bjhd->bijh', q, k) * self.scaleシーケンス次元に沿ったソフトマックス
193 attn = attn.softmax(dim=2)値による乗算
195 res = torch.einsum('bijh,bjhd->bihd', attn, v)形状を次の形式に変更 [batch_size, seq, n_heads * d_k]
197 res = res.view(batch_size, -1, self.n_heads * self.d_k)に変換 [batch_size, seq, n_channels]
199 res = self.output(res)スキップ接続を追加
202 res += x形状に変更 [batch_size, in_channels, height, width]
205 res = res.permute(0, 2, 1).view(batch_size, n_channels, height, width)208 return res211class DownBlock(Module):218 def __init__(self, in_channels: int, out_channels: int, time_channels: int, has_attn: bool):
219 super().__init__()
220 self.res = ResidualBlock(in_channels, out_channels, time_channels)
221 if has_attn:
222 self.attn = AttentionBlock(out_channels)
223 else:
224 self.attn = nn.Identity()226 def forward(self, x: torch.Tensor, t: torch.Tensor):
227 x = self.res(x, t)
228 x = self.attn(x)
229 return x232class UpBlock(Module):239 def __init__(self, in_channels: int, out_channels: int, time_channels: int, has_attn: bool):
240 super().__init__()入力は、in_channels + out_channels
U-Netの前半から同じ解像度の出力を連結しているためです。
243 self.res = ResidualBlock(in_channels + out_channels, out_channels, time_channels)
244 if has_attn:
245 self.attn = AttentionBlock(out_channels)
246 else:
247 self.attn = nn.Identity()249 def forward(self, x: torch.Tensor, t: torch.Tensor):
250 x = self.res(x, t)
251 x = self.attn(x)
252 return xミドルブロック
a とResidualBlock
AttentionBlock
、ResidualBlock
の後に続く別のものを組み合わせます。このブロックは U-Net の最低解像度で適用されます
255class MiddleBlock(Module):263 def __init__(self, n_channels: int, time_channels: int):
264 super().__init__()
265 self.res1 = ResidualBlock(n_channels, n_channels, time_channels)
266 self.attn = AttentionBlock(n_channels)
267 self.res2 = ResidualBlock(n_channels, n_channels, time_channels)269 def forward(self, x: torch.Tensor, t: torch.Tensor):
270 x = self.res1(x, t)
271 x = self.attn(x)
272 x = self.res2(x, t)
273 return x次の方法でフィーチャマップをスケールアップします。
276class Upsample(nn.Module):281 def __init__(self, n_channels):
282 super().__init__()
283 self.conv = nn.ConvTranspose2d(n_channels, n_channels, (4, 4), (2, 2), (1, 1))285 def forward(self, x: torch.Tensor, t: torch.Tensor):t
は使われていませんが、ResidualBlock
アテンションレイヤーの関数シグネチャとのマッチングのため引数には残されています。
288 _ = t
289 return self.conv(x)フィーチャマップを次の方法でスケールダウンします。
292class Downsample(nn.Module):297 def __init__(self, n_channels):
298 super().__init__()
299 self.conv = nn.Conv2d(n_channels, n_channels, (3, 3), (2, 2), (1, 1))301 def forward(self, x: torch.Tensor, t: torch.Tensor):t
は使われていませんが、ResidualBlock
アテンションレイヤーの関数シグネチャとのマッチングのため引数には残されています。
304 _ = t
305 return self.conv(x)ユーネット
308class UNet(Module):image_channels画像内のチャンネル数です。RGB 用です。n_channels画像を変換する最初の特徴マップのチャンネル数ですch_multsは、各解像度のチャンネル番号のリストです。チャンネル数はch_mults[i] * n_channelsis_attnそれぞれの解像度で注意を向けるべきかどうかを示すブーリアンのリストですn_blocksUpDownBlocksは各解像度でのの数です
313 def __init__(self, image_channels: int = 3, n_channels: int = 64,
314 ch_mults: Union[Tuple[int, ...], List[int]] = (1, 2, 2, 4),
315 is_attn: Union[Tuple[bool, ...], List[int]] = (False, False, True, True),
316 n_blocks: int = 2):324 super().__init__()解像度の数
327 n_resolutions = len(ch_mults)画像をフィーチャマップに投影
330 self.image_proj = nn.Conv2d(image_channels, n_channels, kernel_size=(3, 3), padding=(1, 1))時間埋め込みレイヤー。時間埋め込みにはチャンネルがあります n_channels * 4
333 self.time_emb = TimeEmbedding(n_channels * 4)U-Netの前半-解像度の低下
336 down = []チャンネル数
338 out_channels = in_channels = n_channels各解像度について
340 for i in range(n_resolutions):この解像度での出力チャンネル数
342 out_channels = in_channels * ch_mults[i][追加] n_blocks
344 for _ in range(n_blocks):
345 down.append(DownBlock(in_channels, out_channels, n_channels * 4, is_attn[i]))
346 in_channels = out_channels最後の解像度を除くすべての解像度のダウンサンプル
348 if i < n_resolutions - 1:
349 down.append(Downsample(in_channels))モジュールセットを組み合わせる
352 self.down = nn.ModuleList(down)ミドルブロック
355 self.middle = MiddleBlock(out_channels, n_channels * 4, )U-Netの後半-解像度の向上
358 up = []チャンネル数
360 in_channels = out_channels各解像度について
362 for i in reversed(range(n_resolutions)):n_blocks
同じ解像度で
364 out_channels = in_channels
365 for _ in range(n_blocks):
366 up.append(UpBlock(in_channels, out_channels, n_channels * 4, is_attn[i]))チャンネル数を減らすための最後のブロック
368 out_channels = in_channels // ch_mults[i]
369 up.append(UpBlock(in_channels, out_channels, n_channels * 4, is_attn[i]))
370 in_channels = out_channels前回を除くすべての解像度でサンプルをアップ
372 if i > 0:
373 up.append(Upsample(in_channels))モジュールセットを組み合わせる
376 self.up = nn.ModuleList(up)最終正規化と畳み込み層
379 self.norm = nn.GroupNorm(8, n_channels)
380 self.act = Swish()
381 self.final = nn.Conv2d(in_channels, image_channels, kernel_size=(3, 3), padding=(1, 1))x形がある[batch_size, in_channels, height, width]t形がある[batch_size]
383 def forward(self, x: torch.Tensor, t: torch.Tensor):タイムステップの埋め込みを入手
390 t = self.time_emb(t)イメージプロジェクションを取得
393 x = self.image_proj(x)h
接続をスキップできるように、出力を各解像度で保存します
396 h = [x]ユーネット前半
398 for m in self.down:
399 x = m(x, t)
400 h.append(x)中央 (下部)
403 x = self.middle(x, t)ユーネット後半
406 for m in self.up:
407 if isinstance(m, Upsample):
408 x = m(x, t)
409 else:U-Netの前半からスキップ接続を取得して連結する
411 s = h.pop()
412 x = torch.cat((x, s), dim=1)414 x = m(x, t)最終的な正規化と畳み込み
417 return self.final(self.act(self.norm(x)))